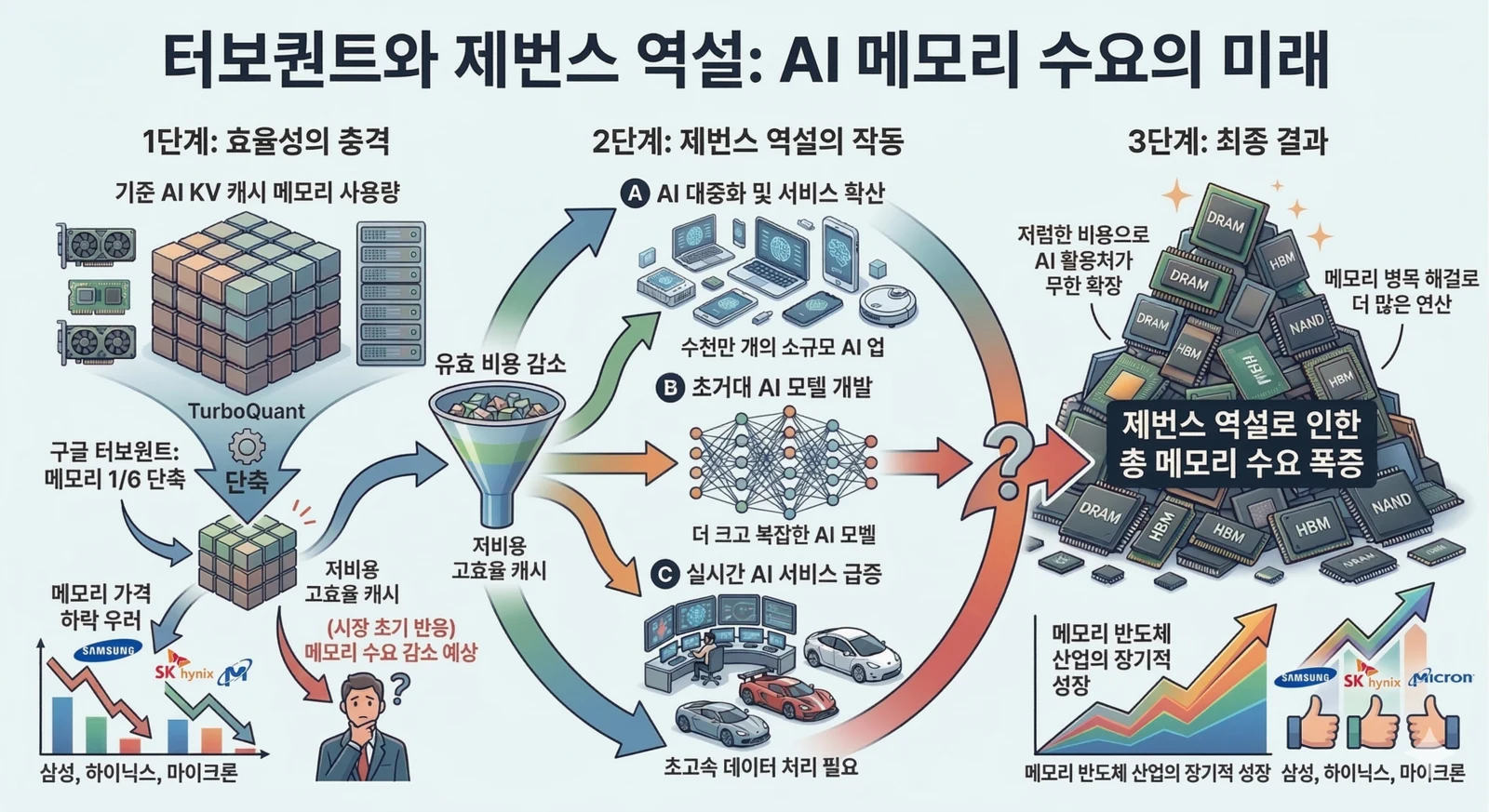
2026년 3월 넷째 주 메모리 관련 종목이 급락했을 때, 시장은 비교적 단순한 서사로 이 움직임을 설명했다. Google Research가 TurboQuant를 소개했고, 이 기술이 AI 추론 과정에서 필요한 메모리를 크게 줄일 수 있다면 결국 AI 인프라 투자에서 메모리 반도체의 중요성도 낮아질 수 있다는 해석이었다. 이 반응은 직관적으로는 이해하기 쉽다. 동일한 작업을 더 적은 메모리로 처리할 수 있다면, 장기적으로 메모리 칩의 수요 증가율도 둔화될 수 있기 때문이다. 그러나 이런 해석은 기술이 실제로 무엇을 줄이는지, 그리고 효율 개선이 산업 전체 수요에 어떤 방식으로 해석되는지를 지나치게 단순화한다.
불과 며칠 사이에 시장에는 정반대의 반론도 빠르게 퍼졌다. 효율 개선이 반드시 총수요 감소로 이어지는 것은 아니며, 오히려 비용 하락이 새로운 사용처를 열어 장기 수요를 확대할 수 있다는 제번스 역설이 다시 호명되기 시작한 것이다. 이 반론 역시 흥미롭지만, 이를 곧바로 메모리 업황 낙관론의 근거로 삼는 것도 성급하다. 이번 논쟁의 핵심은 TurboQuant가 대단한 기술인가 아닌가가 아니라, 특정 병목의 완화가 전체 메모리 수요에 어떤 경로로 전이되는가에 있다. 이 글은 그 질문을 중심에 두고, 사실 관계와 해석의 범위를 분리해 정리한다.
요약
- 사실: Google Research는 2026년 3월 24일 TurboQuant를 공식 블로그에서 소개했고, 관련 논문은 그보다 앞선 2025년 4월 arXiv에 공개돼 있었다.
- 사실: Google은 TurboQuant가 KV 캐시 메모리를 최소 6배 줄이고, 어텐션 로짓 계산에서 H100 기준 최대 8배 속도 향상을 낼 수 있다고 설명했다.
- 사실: 논문 초록은 KV 캐시 양자화에서 채널당 3.5비트 수준에서는 사실상 품질 중립, 채널당 2.5비트에서는 경미한 품질 저하를 보고한다.
- 사실: 2026년 3월 28일 기준 주요 시장 매체들은 이 발표 이후 메모리 관련 종목이 급락했다고 보도했다.
- 사실: BofA와 Morgan Stanley 쪽 해석은 이번 충격이 과도하며, 메모리 수요 전체를 재평가할 근거로 보기에는 이르다는 쪽에 가까웠다.
- 사실: 학계의 Jevons 논의는 효율 개선이 총수요 확대를 부를 수 있다고 보지만, 그 크기는 가격 전이, 수요 탄력성, 사업자 인센티브 같은 조건에 달려 있다고 본다.
- 추정: TurboQuant는 일부 추론 워크로드에서 메모리 집약도를 실질적으로 낮출 가능성이 높다.
- 추정: 그러나 총 AI 메모리 수요는 단위 비용 하락, 사용량 증가, 긴 문맥 확산, 동시성 확대의 영향을 동시에 받기 때문에 단순히 감소한다고 보기 어렵다.
- 의견: 이번 급락은 기술 변화 자체보다도, 기술 뉴스를 시장이 어떤 내러티브로 해석했는지가 더 크게 작용한 사례에 가깝다.
1. 이번 논쟁은 어디서 시작됐나
Google Research는 2026년 3월 24일 TurboQuant: Redefining AI efficiency with extreme compression라는 제목의 글을 통해 TurboQuant를 다시 강하게 부각했다. 이 블로그 글은 단순한 연구 소개를 넘어서, KV 캐시와 벡터 검색이라는 AI 시스템의 메모리 병목을 동시에 겨냥하는 이론적·실용적 기법이라는 점을 강조했다. 같은 주제의 논문은 이미 arXiv에 공개되어 있었지만, 이번에는 Google Research가 직접 블로그 형식으로 메시지를 정리하면서 투자자와 업계 전반의 관심이 급격히 커졌다.
시장에 가장 강하게 남은 표현은 두 가지였다. 첫째는 KV 캐시 메모리를 최소 6배 줄일 수 있다는 주장이고, 둘째는 H100에서 어텐션 로짓 계산 기준 최대 8배의 성능 향상이 가능하다는 설명이었다. 투자자 입장에서는 이 두 문장만으로도 충분히 위협적으로 들릴 수 있다. AI 추론 확산의 대표 수혜주로 분류되던 메모리 반도체 업종은 그동안 AI가 커질수록 메모리도 더 많이 필요하다는 전제를 기반으로 높은 기대를 받아왔기 때문이다. 따라서 메모리를 훨씬 덜 써도 된다는 메시지는 곧바로 업황 논리의 역전으로 받아들여졌다.
Business Insider는 2026년 3월 28일 기사에서 Google의 발표 이후 Micron, Sandisk, Western Digital, Seagate 등 메모리 관련 종목이 큰 폭으로 밀렸다고 보도했다. 같은 날 MarketWatch도 Micron이 전날 약 7% 하락했으며, 투자자들이 TurboQuant를 메모리 수요 둔화의 신호로 해석하고 있다고 전했다. 여기서 중요한 점은, 당시 주가 반응이 실제 실적 악화나 발주 취소에 대한 확인이 아니라 앞으로 그럴지도 모른다는 기대 변화에 의해 움직였다는 것이다.
2. TurboQuant는 정확히 무엇을 줄이는 기술인가
이번 논쟁에서 가장 먼저 정리해야 할 부분은 메모리라는 단어를 하나의 덩어리처럼 다루면 안 된다는 점이다. TurboQuant가 직접 겨누는 대상은 모델 전체 메모리 사용량이 아니라 주로 KV 캐시와 벡터 검색 인프라다. KV 캐시는 추론 과정에서 이전 토큰의 key와 value를 저장해두는 공간으로, 문맥 길이가 길어질수록 빠르게 커지고, 동시에 처리하는 세션 수가 늘어날수록 비용 부담이 급격히 확대된다. 긴 문맥 기반 대화, 에이전트, RAG, 대규모 다중 사용자 추론 서비스에서 특히 민감한 병목이 되는 이유가 여기에 있다.
따라서 TurboQuant가 줄이는 것은 AI 전체에 필요한 메모리가 아니라 특정 유형의 추론에서 특정 구간이 요구하는 메모리라고 표현하는 편이 정확하다. 이 차이는 투자 해석에서 매우 중요하다. AI 인프라의 메모리 부담은 학습용 메모리, 추론용 가중치 메모리, KV 캐시, 네트워크 버퍼와 통신 부담, 저장장치와 벡터 인덱스 메모리처럼 여러 층위로 나뉜다. TurboQuant는 이 가운데 KV 캐시와 벡터 검색에서 강한 의미를 가지지만, 그 사실만으로 HBM 전체 수요나 메모리 업황 전반을 바로 계산하는 것은 무리다.
Google Research의 설명을 따르면 TurboQuant는 온라인 벡터 양자화를 통해 메모리 오버헤드를 최소화하면서도 정확도 손실을 줄이는 데 초점을 맞춘다. 구체적으로는 PolarQuant와 Quantized Johnson-Lindenstrauss 같은 기법을 조합해, KV 캐시 압축에서 흔히 발생하는 왜곡과 오버헤드 문제를 줄이려 한다. 이론적으로는 매우 흥미롭고, 실제 실험 결과도 꽤 인상적이다. 다만 투자자에게 필요한 질문은 기술적으로 가능한가를 넘어 어떤 작업 부하에, 얼마나 빨리, 어떤 비용 구조로 채택되는가이다.
조금 더 구체적으로 보면 Google은 먼저 무작위 회전으로 벡터의 에너지를 여러 좌표에 퍼뜨린 뒤, PolarQuant로 이를 극좌표 형태에 가깝게 다루면서 기존 양자화가 짊어지던 정규화 상수와 메타데이터 부담을 줄인다고 설명한다. 여기에 잔차를 보정하는 1비트 QJL을 결합해 내적 추정의 편향을 낮춘다. arXiv 초록은 이 접근을 data-oblivious한 온라인 벡터 양자화로 설명하며, KV 캐시 양자화에서 채널당 3.5비트에서는 absolute quality neutrality, 채널당 2.5비트에서는 marginal quality degradation을 보였다고 적고 있다. 즉 TurboQuant의 핵심은 단순히 비트폭을 낮추는 것이 아니라, 압축 때문에 늘어나는 메타데이터와 왜곡 비용까지 함께 통제하려는 데 있다.
또 하나 중요한 점은 핵심 수치의 범위다. Google이 강조한 최대 8배 성능 향상은 H100에서 attention logits 계산 구간을 32비트 비양자화 키와 비교한 결과이며, 공식 블로그도 이를 JAX 기준선 대비 어텐션 계산 속도 향상으로 명시한다. 이는 모델 전체의 처음부터 끝까지의 추론 속도가 모든 환경에서 8배 빨라진다는 뜻이 아니다. 실제 서비스에서는 비트 포장과 해제, 커널 최적화, 메모리 접근 패턴, 나머지 행렬곱 구간의 비중에 따라 체감 개선 폭이 달라질 수 있다. 따라서 투자 해석도 8배 빨라졌다가 아니라 특정 병목 구간의 계산 비용이 크게 낮아질 수 있다는 수준에서 읽는 편이 정확하다.
3. 시장이 빠르게 메모리 수요 감소로 해석한 이유
시장이 보인 초기 반응은 이해하기 어렵지 않다. 추론 비용에서 의미 있는 비중을 차지하는 메모리 병목이 줄어든다면, AI 인프라 수요의 한 축이 약해진다고 해석할 수 있기 때문이다. 특히 최근 메모리 업종에 붙어 있던 프리미엄은 단순한 평균 회복이 아니라 AI 시대의 구조적 병목 산업이라는 서사 위에 형성돼 있었다. 그런 상황에서 병목 완화 기술이 등장하면, 밸류에이션이 빠르게 흔들리는 것은 자연스럽다.
그러나 이 반응은 세 가지 중요한 전제를 생략한다. 첫째, 단위당 메모리 사용량이 줄어드는 것과 총 메모리 수요가 줄어드는 것은 별개의 문제다. 둘째, 추론 메모리 절감이 곧바로 AI 학습 투자나 고성능 가속기 투자 축소로 이어진다고 볼 수 없다. 셋째, 메모리 시장은 DRAM, NAND, HBM, 서버 메모리, 엣지 메모리로 분화되어 있으며, 각 영역은 동일한 방식으로 영향을 받지 않는다.
예를 들어 HBM 수요의 핵심은 여전히 고성능 가속기와 묶인 대역폭 집약적 워크로드다. 반면 KV cache 최적화는 긴 문맥 추론과 대규모 동시성에서 직접적인 의미를 가진다. 모델이 더 길고, 더 자주, 더 동시에 실행된다면 KV cache 병목이 완화되더라도 시스템 전체가 요구하는 메모리 총량과 메모리 대역폭은 다시 커질 수 있다. 결국 시장이 최초에 적용한 메모리 사용량 감소 = 메모리 칩 수요 감소라는 식은 지나치게 선형적이었다.
4. 제번스 역설은 왜 다시 거론됐나
이 지점에서 등장한 개념이 제번스 역설이다. 제번스 역설은 효율 개선이 단순한 절약으로 끝나지 않고, 오히려 비용 하락을 통해 수요를 더 크게 확대할 수 있다는 경제학적 통찰이다. NPR Planet Money는 2025년 2월 4일 기사에서 이 개념을 설명하며, Microsoft CEO 사티아 나델라가 DeepSeek 충격 당시 AI가 더 효율적이고 더 접근 가능해질수록 사용은 오히려 폭증할 것이라는 취지로 제번스 역설을 언급했다고 정리했다.
같은 기사에서 Stanford의 Erik Brynjolfsson은 제번스형 반응이 성립하기 위한 조건을 비교적 명확하게 제시한다. 첫째, 생산성이 실제로 개선되어야 한다. 둘째, 생산성 향상이 가격 하락이나 비용 절감으로 전이되어야 한다. 셋째, 그렇게 낮아진 가격에 대해 수요가 충분히 탄력적으로 반응해야 한다. 이 세 조건을 AI에 대입하면 왜 많은 사람이 TurboQuant를 오히려 수요 확대의 촉매로 보는지 이해할 수 있다.
추론 메모리 비용이 낮아지면 기업은 더 긴 컨텍스트를 활성화할 수 있고, 더 많은 세션을 동시에 유지할 수 있으며, API 가격을 낮추거나 그전에는 경제성이 맞지 않던 기능을 제품에 넣을 수 있다. 장문 요약, 대규모 검색, 코딩 보조, 음성 비서, 장기 에이전트, 산업용 분석 같은 서비스는 비용이 낮아질수록 사용량이 크게 늘 가능성이 있다. 이런 관점에서 보면 TurboQuant는 메모리 수요를 죽이는 기술이 아니라, 오히려 AI 사용량 자체를 확장하는 기술로 읽힐 수 있다.
5. 그러나 제번스 역설은 만능 반박이 아니다
여기서 다시 한 번 주의가 필요하다. 제번스 역설은 효율 개선이 항상 총수요 증가로 이어진다고 주장하는 기계적 법칙이 아니다. 최종 수요가 충분히 탄력적이지 않으면 효율 개선은 총량 감소로 연결될 수 있다. 또한 사용량이 늘더라도 그 증가분이 반드시 현재 메모리 밸류체인의 기존 승자들에게 같은 비율로 돌아간다고 볼 수도 없다.
예를 들어 더 많은 AI가 엣지나 온디바이스로 분산된다면, HBM보다 다른 형태의 메모리 구조가 상대적으로 중요해질 수 있다. 또 어떤 애플리케이션은 TurboQuant 같은 양자화 기술보다 더 작은 모델, 더 나은 라우팅, MLA 같은 구조적 변화, 혹은 모델 아키텍처 개선을 통해 메모리 부담을 줄일 수 있다. 따라서 제번스 역설은 메모리 수요가 반드시 폭증한다는 낙관론의 근거라기보다, 효율 향상만 보고 총수요 감소를 단정할 수 없다는 경고로 이해하는 편이 더 정확하다.
경제학적으로도 이 지점이 중요하다. 제번스 역설이 작동하려면 가격 하락이 수요 확대를 충분히 자극해야 한다. 그런데 모든 AI 수요가 그렇게 탄력적인 것은 아니다. 기업용 소프트웨어, 검색, AI 에이전트, 산업 자동화, 로컬 모델, 엣지 AI는 각각 가격 탄력성이 다르다. 따라서 TurboQuant의 경제적 효과는 하나의 보편적 결론으로 환원되기보다, 워크로드별로 분해해서 봐야 한다.
학계의 최근 논의도 대체로 같은 방향이다. 2025년 FAccT에 발표된 Alexandra Sasha Luccioni, Emma Strubell, Kate Crawford의 논문은 AI 효율 개선 논의가 직접 효과에만 매달리고, 간접적 리바운드 효과를 과소평가하는 경향이 있다고 지적한다. 동시에 이 논문은 rebound effect의 크기가 기술 자체만으로 결정되지 않으며, 사업자 인센티브, 시장 구조, 거버넌스, 사회적 규범에 좌우된다고 본다. 이를 메모리 수요 논쟁에 옮기면, 효율이 높아졌으니 총수요가 반드시 폭발한다도 아니고 효율이 높아졌으니 총수요가 반드시 줄어든다도 아니다. 핵심은 절감된 비용이 가격 인하와 사용 확대, 더 긴 문맥과 더 높은 동시성으로 실제 전이되느냐이다.
6. 전문가들의 해석은 어떻게 갈렸나
기술 측면에서 Google Research는 상당히 강한 톤을 유지했다. Google은 TurboQuant가 LongBench, Needle-in-a-Haystack 등 장문 벤치마크에서 손실 없이 동작했다고 설명했고, KV bottleneck 완화와 벡터 검색 효율 개선을 동시에 강조했다. 기술 연구자 입장에서 이는 충분히 큰 성과다. 특히 메모리 오버헤드를 줄이면서 왜곡률을 통제할 수 있다는 점은 장문 추론 인프라에 직접적인 함의를 가진다.
반면 시장 전문가들은 보다 보수적인 태도를 취했다. Business Insider에 따르면 Bank of America의 Vivek Arya는 이번 매도세가 과도하다고 평가했다. 그의 논리는 비교적 명료하다. 효율 개선 기술은 이미 여러 차례 등장해 왔고, 진짜 수요의 증거는 여전히 hyperscaler들의 AI capex다. 다시 말해, 특정 병목 완화 기술 하나가 등장했다고 해서 AI 인프라 투자 사이클 전체를 약세로 돌려 읽을 근거는 부족하다는 것이다.
MarketWatch가 전한 Morgan Stanley의 Joseph Moore 역시 비슷한 문제의식을 보였다. 그는 TurboQuant가 AI 시스템의 좁은 한 부분을 겨냥한 기술이며, HBM의 중요성 자체를 부정하는 증거로 읽히지는 않는다고 봤다. 이 해석은 투자 관점에서 특히 중요하다. 메모리라는 큰 분류 안에서도 어떤 영역이 가장 공급 제약이 심하고, 어떤 영역이 실제 시스템 병목에 더 직접적으로 연결되는지에 따라 시장의 반응은 달라질 수 있기 때문이다.
경제학적 해석을 제공한 Brynjolfsson의 입장도 함께 볼 필요가 있다. 그의 프레임은 효율 개선을 단순한 절감이 아니라 가격 하락과 수요 탄력성의 함수로 이해한다. 이 관점은 메모리 수요 전망을 볼 때도 유용하다. 핵심은 메모리를 덜 쓰는가가 아니라 메모리 절감이 AI 이용량 확대를 어디까지 자극하는가이다.
7. 해외 주요 기술 커뮤니티는 무엇을 봤나
흥미로운 점은 기술 커뮤니티의 반응이 주식시장보다 훨씬 세분화되어 있었다는 것이다. 관련 토론에서는 강한 기대와 냉정한 회의론이 동시에 나타났다. 기대 쪽의 논리는 비교적 단순했다. 만약 논문이 주장하는 수준의 압축이 실제 구현에서도 재현된다면, 같은 RAM으로 훨씬 긴 컨텍스트를 다룰 수 있고, 로컬 LLM이나 엣지 배포의 경제성이 크게 개선될 수 있다는 것이다. 일부 사용자는 MLX 등으로 포팅을 시도하면서 실제 활용 가능성에 높은 관심을 보였다.
반면 회의론은 훨씬 구체적이었다. 여러 사용자는 논문에서 말하는 최대 8배 개선이 모델 전체 추론 속도가 아니라 어텐션 로짓 계산 구간의 개선이라는 점을 지적했다. 또한 비트 포장, 커널 최적화, 메모리 접근 패턴 개선이 충분히 뒤따르지 않으면 전체 구간 관점에서는 오히려 전체 속도가 기대보다 덜 개선되거나 심지어 느려질 수 있다는 의견도 나왔다. 이런 반응은 기술을 실제 배포 관점에서 본다는 점에서 매우 중요하다.
이 점은 MLX 포팅 논의에서 더 구체적으로 드러난다. 해당 구현자는 KV 캐시 점유량이 실제로 줄어들고 출력 일관성도 유지된다고 보고했지만, 동시에 가장 큰 병목은 비트 포장과 해제이며, 이 때문에 현재 구현은 표준 FP16보다 빨라지지 못한다고 적었다. 연구 논문의 압축률과 실제 시스템의 전체 처리량 사이에는 커널 수준의 엔지니어링 계층이 하나 더 있다는 뜻이다. 투자 관점에서도 이 간극은 중요하다. 논문이 성립한다고 해서 곧바로 산업 전반의 비용 구조가 같은 속도로 바뀌는 것은 아니기 때문이다.
또 다른 층위의 논쟁은 연구 계보에 대한 문제제기였다. 몇몇 연구자는 무작위 회전과 편향 보정의 결합이 완전히 새로운 발상이라기보다 기존 분산 추정·양자화 계열 연구, 특히 DRIVE와의 연속선상에서 읽혀야 한다고 주장했다. 다른 한쪽에서는 회전이 좌표 분포를 예측 가능하게 만들어 양자화 효율을 높이지만, 그 과정에서 모델이 학습한 구조를 일부 평탄화할 수 있다는 우려도 제기됐다. 이런 논의는 TurboQuant의 실험 결과를 부정하지는 않지만, 시장이 받아들인 마법 같은 압축 기술이라는 이미지를 현실적인 기술 토론의 수준으로 끌어내린다.
8. 현재 시점에서 가장 타당한 해석은 무엇인가
이번 급락이 완전히 근거 없는 공포였다고 보기는 어렵다. TurboQuant는 실제 기술 진보이며, 긴 문맥 추론과 벡터 검색에서 메모리 효율을 크게 높일 수 있는 잠재력을 보여준다. 따라서 일부 추론 워크로드에서는 바이트 기준 메모리 수요가 실제로 줄어들 가능성이 있다. 여기까지는 사실에 가깝다.
다만 이 사실을 시스템 전체 수요 전망으로 곧바로 확장하는 순간 오류가 커진다. TurboQuant가 직접 줄이는 것은 어디까지나 KV 캐시와 일부 벡터 검색 인프라의 메모리 부담이지, 모델 가중치 자체나 대규모 학습에 필요한 메모리, 그리고 연산량 전체가 아니다. 기술 구현 논의가 반복해서 보여준 것도 바로 이 구분이다. 긴 문맥에서 캐시 부담이 내려가더라도, 여전히 가중치 적재와 행렬곱, 네트워크, 패키징, 대역폭 같은 다른 병목은 남아 있다. 따라서 KV 캐시 압축 = AI 메모리 수요 붕괴라는 등식은 성립하기 어렵다.
그러나 그 다음 단계, 즉 메모리 관련 기업의 장기 수요가 구조적으로 무너질 것이다라는 결론은 아직 매우 이르다. 그 결론이 성립하려면 적어도 네 가지가 확인되어야 한다. 첫째, TurboQuant가 실험적 결과를 넘어 대규모 서비스 환경에 빠르게 채택되어야 한다. 둘째, 채택 이후에도 사용량 증가보다 절감 효과가 더 커야 한다. 셋째, 그 절감 효과가 HBM 같은 핵심 수요층까지 직접 깎아야 한다. 넷째, hyperscaler capex와 accelerator 수요도 함께 둔화되어야 한다. 2026년 3월 28일 기준 이 네 조건 가운데 확정된 것은 거의 없다.
오히려 반대 시나리오도 충분히 설득력이 있다. 효율이 올라가면 더 긴 컨텍스트, 멀티턴 에이전트, 대규모 검색, 더 많은 동시성, 더 낮은 API 가격이 가능해진다. 그렇게 되면 AI 사용량 자체가 커질 수 있고, 단위당 메모리 소비가 줄더라도 총량은 다시 불어날 수 있다. 결국 이번 논쟁의 본질은 요청당 필요한 바이트 수가 아니라 총 요청 수 × 평균 문맥 길이 × 동시성 × 제품 확장 속도라고 보는 편이 맞다.
9. 투자자가 실제로 봐야 할 변수
이 이슈를 투자 관점에서 다룰 때는 세 가지 실수를 피하는 것이 중요하다. 첫째, TurboQuant를 메모리 산업 전체 붕괴의 신호로 읽는 것이다. 둘째, 제번스 역설을 만능 반박처럼 사용하는 것이다. 셋째, 메모리라는 단어를 지나치게 단일한 산업처럼 다루는 것이다.
보다 실질적으로는 다음 변수들을 함께 확인할 필요가 있다.
- hyperscaler capex 가이던스와 실제 집행 속도
- HBM 공급 계약, 증설 일정, 수율과 패키징 병목
- 긴 문맥 추론과 에이전트 작업 부하의 실제 사용 증가
- TurboQuant류 기법의 오픈소스 구현 성숙도와 커널 최적화 수준
- 실제 서비스 환경에서의 전체 구간 성능 개선 검증 여부
또한 HBM, 일반 DRAM, NAND, 엣지 디바이스 메모리는 같은 방향으로 움직이지 않을 수 있다는 점도 중요하다. 어떤 효율화는 특정 수요층을 약하게 만들 수 있지만, 다른 영역에서는 오히려 신규 수요를 키울 수도 있다. 이번 이슈는 단기 주가 충격의 문제이기도 하지만, 더 근본적으로는 AI 인프라 수요를 어떤 프레임으로 해석할 것인가의 문제에 가깝다.
결론
이번 메모리주 급락은 TurboQuant의 기술적 중요성을 보여주는 동시에, 시장이 기술 뉴스를 얼마나 빠르게 단선적인 서사로 해석하는지도 잘 보여준다. 메모리를 덜 쓴다는 사실은 중요하지만, 그것이 곧바로 메모리 수요가 꺾인다는 결론으로 이어지지는 않는다. AI 인프라는 학습과 추론, 모델 크기와 문맥 길이, 동시성과 비용, 제품 확장과 사용자 행동이 서로 얽혀 움직이는 복합 시스템이기 때문이다.
TurboQuant는 특정 병목을 줄이는 기술이다. 따라서 어떤 워크로드에서는 메모리 부담을 직접 낮출 것이고, 그 자체만 보면 메모리 업종에는 분명 부담 요인으로 읽힐 수 있다. 그러나 같은 기술이 AI 사용량의 총합을 키우고 더 넓은 제품군에서 새로운 수요를 창출할 가능성도 동시에 존재한다. 제번스 역설은 바로 이 후자의 가능성을 설명하는 유용한 틀이지만, 그것 역시 수요 탄력성과 실제 채택 속도라는 조건 위에서만 작동한다.
현재 시점에서 가장 균형 잡힌 해석은 이렇다. 이번 급락은 장기 구조 변화의 확정이라기보다, 새 기술을 만난 시장이 가장 단순한 방향으로 먼저 가격을 조정한 사건에 가깝다. 앞으로 중요한 것은 TurboQuant가 메모리 한 바이트의 가치를 얼마나 낮추는가가 아니라, 그러한 효율 개선이 AI 사용량의 총합을 어디까지 확대하느냐이다. 적어도 지금 단계에서는 후자의 가능성을 배제하기 어렵다.
투자자로서
종합해보면 터보퀀트는 초기 매체에서의 파급력에 비해 영향력은 제한적으로 보인다. 우선 학습보다 추론, 그중에서도 KV 캐시와 일부 벡터 검색 같은 비교적 국소적인 메모리 활용 영역으로 제한되어 보인다. 제번스의 역설을 번외로 두고 보더라도, 터보퀀트가 AI 메모리 수요 전체를 비약적으로 줄일 것이라고 보는 것은 무리다.
다만 투자자로서 터보퀀트 변수 확인만으로 향후 주가 흐름을 단정하기는 어렵다. 터보퀀트의 영향이 실제로 크지 않더라도, 메모리 수요의 흐름은 긴 문맥 확산, AI 에이전트 사용 증가, 하이퍼스케일러의 CAPEX, 패키징 병목, 온디바이스 AI 확대처럼 여러 변수에 의해 다시 달라질 수 있다. 즉 이번 논쟁은 수요가 줄어드느냐 늘어나느냐의 이분법보다, 어떤 수요가 줄고 어떤 수요가 새로 생기느냐의 문제에 더 가깝다.
여기에 더해 현재 시장은 AI와 반도체 산업 내부 변수만으로 움직이지도 않는다. 2026년 3월 말 기준으로는 금리, 대선 국면의 정책 불확실성, 대중 수출 규제, 관세, 중동 지정학 리스크와 같은 정치적 변수도 반도체 밸류체인의 멀티플과 투자 심리에 큰 영향을 줄 수 있다. 기술 변화가 장기 방향을 정한다면, 정치와 거시 환경은 그 경로의 속도와 변동성을 바꾼다. 따라서 투자자는 특정 기술 뉴스 하나에 포트폴리오 전체를 걸기보다, 자신의 기존 가설을 계속 업데이트하면서 시장 변화에 맞춘 점진적이고 소극적인 리밸런싱을 준비하는 편이 더 현실적이다.
참고 링크
- Google Research - TurboQuant: Redefining AI efficiency with extreme compression
- arXiv - TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
- arXiv - From Efficiency Gains to Rebound Effects: The Problem of Jevons’ Paradox in AI’s Polarized Environmental Debate
- NPR Planet Money - Why the AI world is suddenly obsessed with a 160-year-old economics paradox
- Business Insider - Memory stocks have tanked, but BofA says the sharp sell-off is overdone
- MarketWatch - Micron’s stock bounces, as an analyst offers a reality check on the recent panic
- Reddit r/LocalLLaMA - [google research] TurboQuant: Redefining AI efficiency with extreme compression
- Reddit r/LocalLLaMA - Looking for feedback: Porting Google’s TurboQuant (QJL) KV Cache compression to MLX
- Hacker News - TurboQuant: Redefining AI efficiency with extreme compression